
今天就來進入 How Google does Machine Learning 的第二章節吧~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第二章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
What it means to be AI first
Two stages of ML
ML in Google products
Demo: ML in Google products
Demo: ML in Google Photos
Google Translate and Gmail
Replacing heuristics
課程地圖
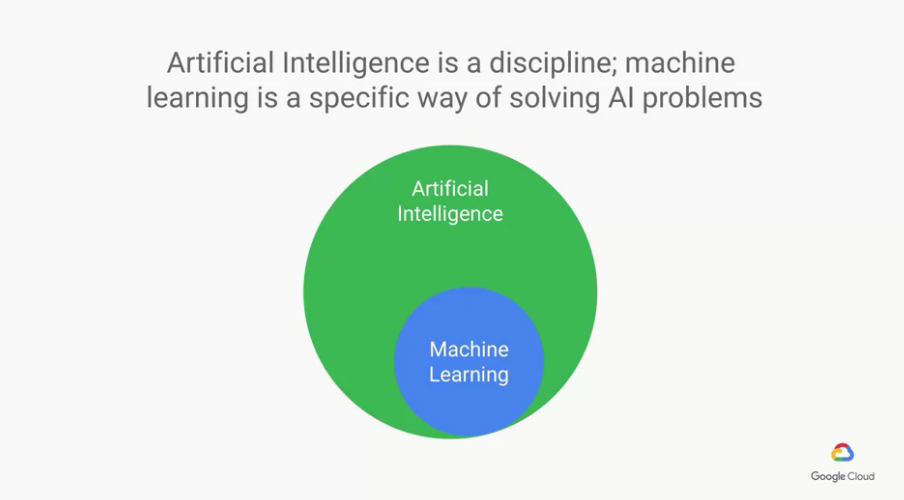
什麼是AI(Artificial Intelligence)? 與ML(machine learning)差在哪?
AI是一種discipline(學科),有許多的theory and methods
什麼是ML(machine learning)?
ML是一種toolset(工具集),ML就是拿來解AI問題的
(ML是讓machine訓練與學習用的,他們沒有intelligent,但會become intelligent)
課程地圖
這邊以 Supervised Learning (監督式學習)作為舉例:
ML model的本身就是一種數學函數(math functions)
我們的目標 = 讓input經過我們的數學函數(math functions)後產生label
ML 需要的就是 labeled examples = input + label(ture anwser)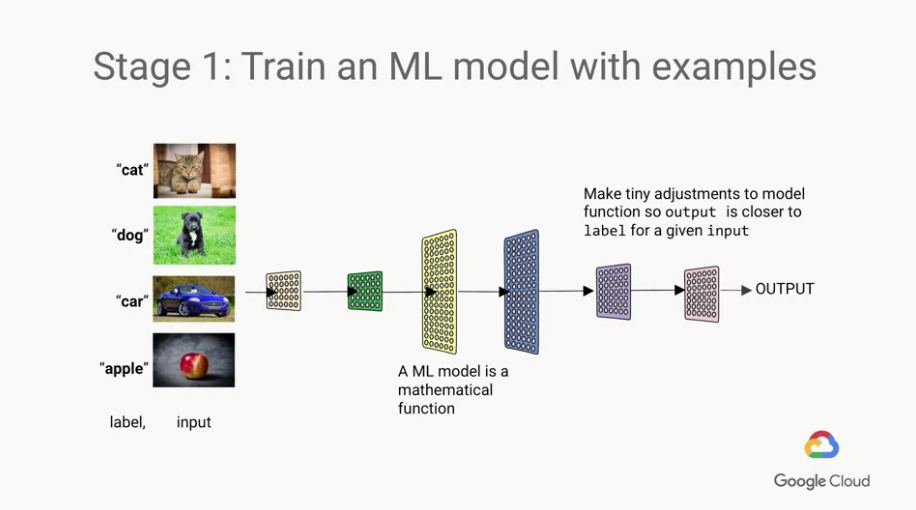
經過這樣的學習之後,即使是沒看過的貓,我們的模型也能夠正確的判斷他是貓。
但要達成這樣的事情,關鍵是我們會需要非常非常多的資料。
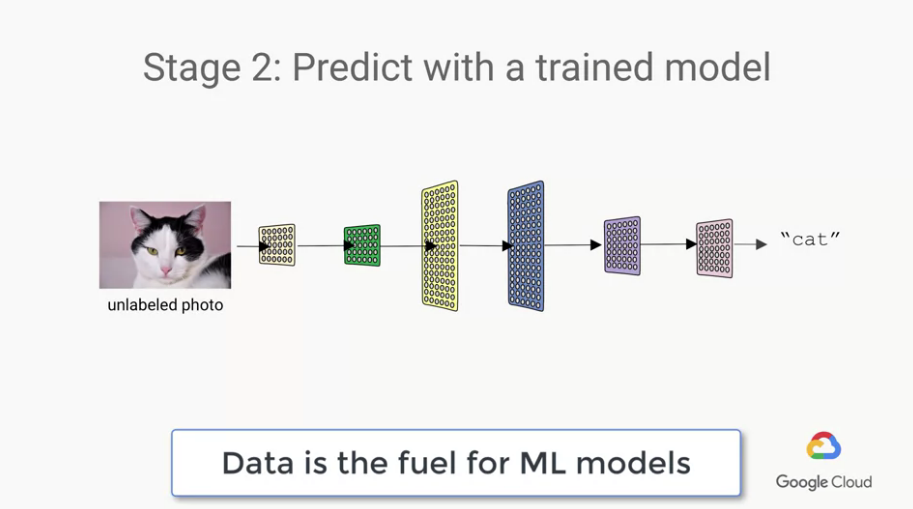
所以一整個ML模型的產生(two stages)的流程如下圖:
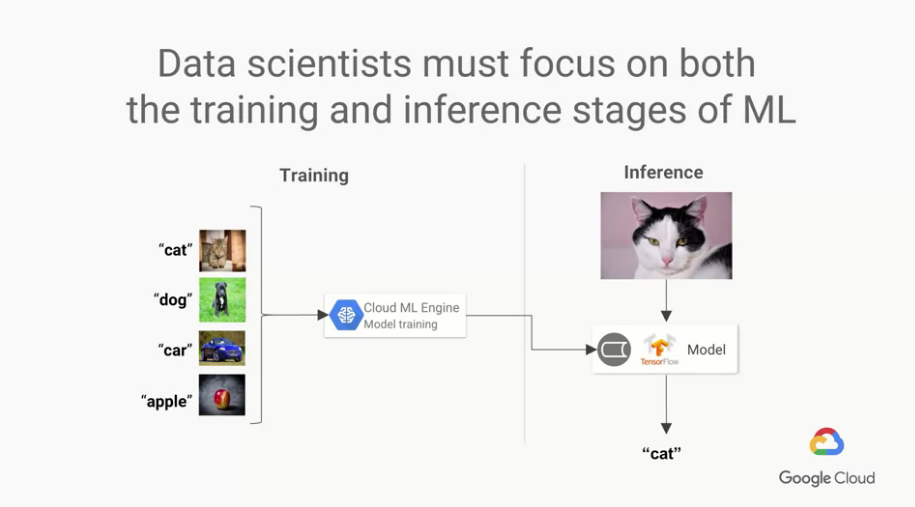
一個好的ML模型,不能單單只有在Stage 1上面下非常多的功夫,
很多研究數據的人員,甚至是書本、教科書都過度強調Stage 1的training重要性,
但這裡就會掉入一個陷阱,過度強調Stage 1模型訓練,
而不進入Stage 2的生產階段,往往實際上所訓練出來的ML模型都是沒有實際用途的。

課程地圖
每層layer都是一個function,
一整個model = functions,也稱之為Neural Network
然而Neural Network(NN)也只是一種數學模型而已
其他還有常用在ML的數學模型像是: linear methods, decision trees, radial basis functions, ensembles of trees, radial basis functions
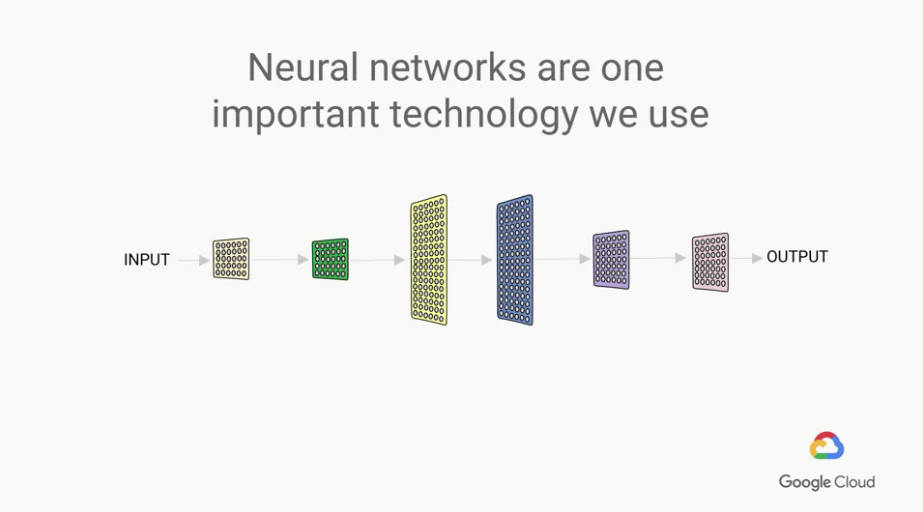
最早的NN沒有這麼多層layer,只有一層,
然而這也代表著為何最近ML才紅起來的幾個關鍵原因:
越多層(deep NNs)自然需要更強大的電腦運算能力
越多層(deep NNs)需要更多的資料來調整參數
越多層(deep NNs)需要更佳的計算技巧,否則會花非常大量的時間運算,甚至有大量沒幫助的參數
總和以上原因,這些都是在近幾年才被解決的問題,
所以google才能在近幾年有近4000個deep learning的應用。
Google的產品中到處充滿了ML models,
而且通常一個產品可能充滿了無數個ML models,而非只有"一個"
一個產品中會碰到許多複雜的問題,而我們必須還要去拆解問題,
拆解一個小問題之後,才能針對一個小問題去想出一個ML model去解決它。
One solution needs many ML models.
舉例:how to forecast rather an item will go out of stock?
這不會是只靠一個ML model能解決的問題,
光這個問題我們就能拆成三個小問題,
但三個小問題之中又不見得只靠一個ML model就能解決,
也因此我們才會說一個產品可能充滿了無數個ML models,
而且可能才解決了一個複雜的問題。
課程地圖
這個章節大概介紹了 Google Translate 與 Gmail 裡面是怎麼使用 ML的
光是 Google Translate 裡面大概就有這六種不同的ML在使用
Gmail 裡面提到的是跟 Smart Reply (自動回覆)有關的功能,
用到 sequence to sequence model,
不過這樣也表示我們收到的信內容其實有被拿去丟進模型分析了,
雖然不是直接被人拿去閱讀就是(微妙)...... 科技進步與個人資料保護的兩個難題啊。
課程地圖
引用自 Eric Schmidt, the Executive Chairman of the Board at Google 的一段話
"Machine learning," says Eric, "This is the next transformation. The programming paradigm is changing. It's not programming a computer. You teach a computer to learn something and then it does what you want."

這句話非常有趣,裡面沒有提到任何有關於data的事情,
許多人都認為ML只是在做資料結果的預測,
他認為ML是一種可以取代programming的方式,
ML是一種logic,而並非只是在處理data。
舉一個例子,例如我們今天想搜尋"Giants",
google要怎麼知道我們想搜尋的是 San Francisco Giants 還是 New York Giants 呢?
之前google的作法,會在搜尋時先記錄使用者的位置,
依據不同的位置給予不同的搜尋結果(如下圖),
我們可以看到有一堆rules,來決定顯示什麼結果給使用者
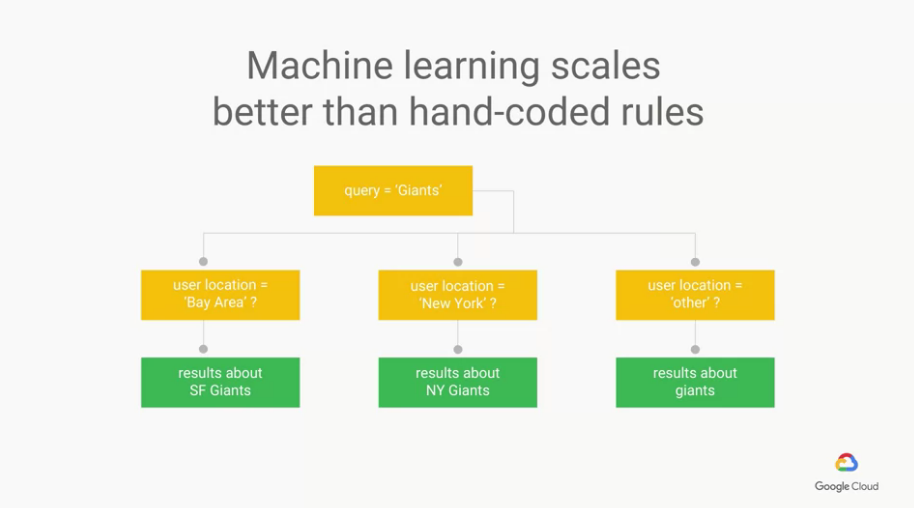
很明顯的,這樣的做法是非常"笨重"的,
這種做法,每當我們想加入一個新的結果,
我們必須再為了多那結果去coding一行判斷式,只為了判斷新的東西,
而且這種做法通常會導致非常難維護。
然而,我們怎麼不嘗試用使用者的搜尋熱度去自動決定結果呢?
因此,依據此概念產生的deep ML model, RankBrain就出現了,
除了依照使用者的搜尋熱度可以自動的動態調整顯示結果,
而且這樣的模型還能夠靠自己就能不斷的進步。

透過 ML 取代 heuristic rules 就是在講像這樣的事情,
ML還能夠替我們解決什麼問題? 如果提到 ML 未來的可能性,
google認為,只要任何是能夠被寫下rules的東西,ML都可以完成,
而且不只侷限於統計分析的這類事情。
Notice that saying that machine learning is a way to replace rules, notice that this is a far more expansive answer to what kinds of problems can machine learning solve.
所以 Google 說自己是 "AI-first" company,
他們認為 ML 在未來可以取代任何 coding 中所寫的 rules,
只要能收集正確的資料,都可以透過 ML 去完成同樣的問題。
我們可以開始用新的角度來思考問題,
我們不用再去想該如何替問題的改變去 coding rules,
我們只需要想怎麼根據資料去訓練模型。我們不用再去想要為了修bug,去替它增加一個新的 rules,
我們只需要想怎麼根據新資料去繼續訓練模型。至於處理那些特別的inputs與特別的rules,
我們只需要想怎麼建立更大規模的模型,來應對這些需要的預測。
(這段真的太猛了...,如果真的實現了等於不用再慢慢地針對情況一一對應coding了,
未來的工程都是在訓練模型,只是將我們coding所實現的rule,皆轉換成訓練的目標)
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
